Single Page Application (SPA) Infrastructure on AWS
Creating a Cloud Infrastructure for Hosting Single Page Applications (SPA) on AWS
Tech Stack
Route-53CloudFrontCloudFront-functionsSimple-Storage-Service-(S3)Amazon-Certificate-Manager-(ACM)
GitHub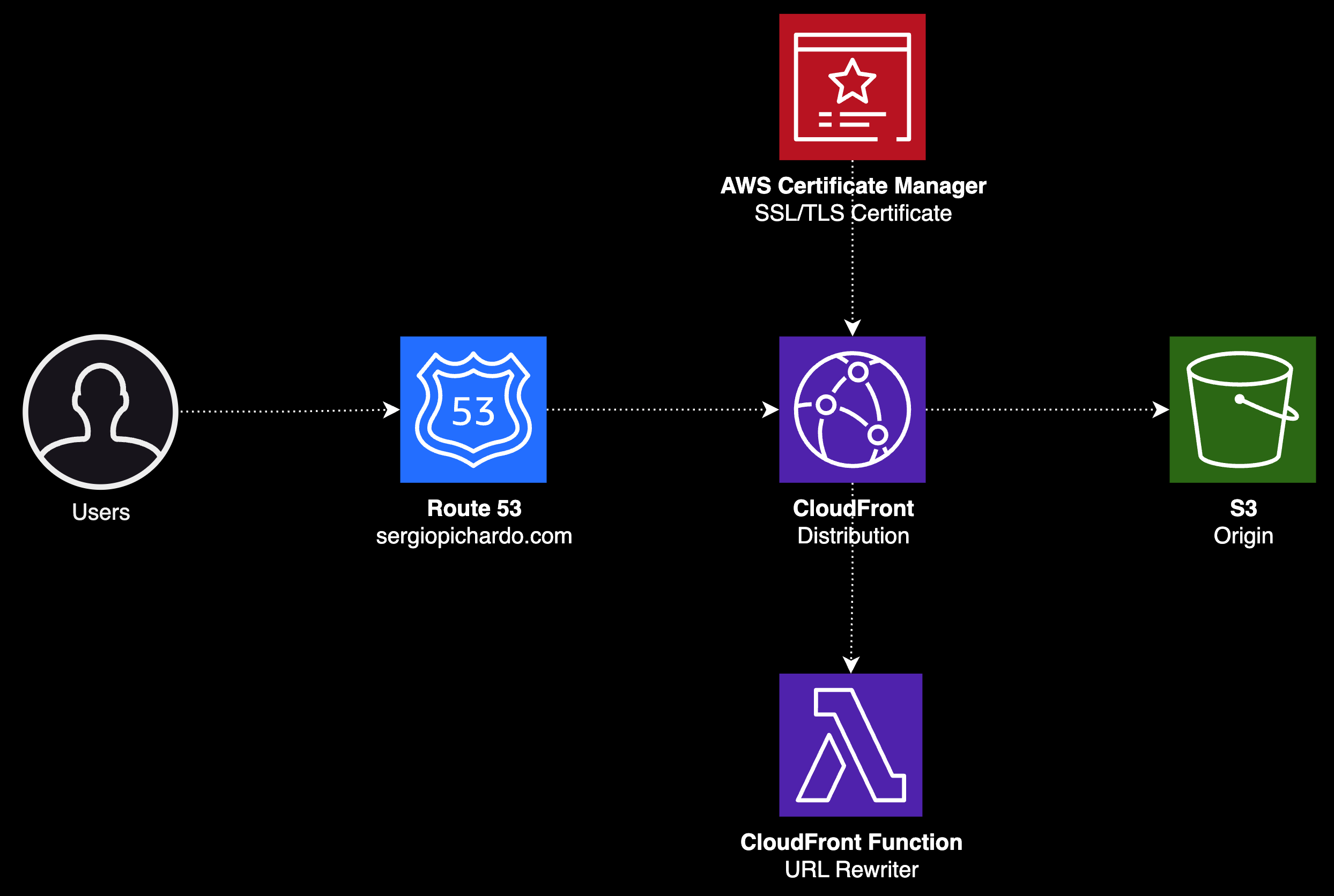
Introduction
A while back, I made the decision to migrate my portfolio website from Vercel to Amazon Web Services. Let me be clear, Vercel it's an exceptional platform, especially with its seamless support for NextJS sites. Their dedication to providing a stellar developer experience is evident. However, much of their process can feel a bit like "magic". Therefore, for my own professional growth, I was keen to look under the hood, aiming to grasp a deeper understanding and control over the underlying infrastructure that powers my website.
So, today we're taking a deep dive into designing and provisioning a cloud infrastructure for Single Page Applications (SPA). We'll navigate through core services I used to migrate my website, pinpoint their limitations, and explore the importance of integrating additional tools. All these steps are essential to successfully host a static website on Amazon Web Services.
The cloud infrastructure we'll be building is centered around four major components: Route 53 for DNS management, CloudFront to serve static assets, AWS Certificate Manager for TLS/SSL certificates, and Simple Storage Service (S3) to store these assets.
I totally understand that navigating the nuances of various AWS services, while simultaneously learning new tools and coding, can be indeed a hassle. So, to address this and facilitate a more structured learning experience, I divided this article into two parts.
In the first part, we'll focus on demystifying the conceptual aspects of hosting a static site on AWS. This foundational knowledge will equip us with the context we need to make informed decisions as we build our infrastructure.
Moving on to the second part, we will shift from theory to practice with a hands-on tutorial. This section aims to demonstrate how to harness the capabilities of Infrastructure as Code (IaC) through TypeScript and the AWS Cloud Development Kit (CDK).
Ready to dive in? Let’s get started!
Demystifying the Conceptual Aspects of Hosting a Static Site on AWS
Naturally, when it comes to housing static assets, S3 is the go-to. It's the logical place to begin our exploration. Let's step back and take a broad overview of S3's offerings and pinpoint which features will aid us in our mission to host a SPA.
Amazon Simple Storage Service (S3)
S3 is a service that provides scalable object storage. It allows developers to store and retrieve large amounts of data at any time, making it a popular choice for backup and storage, hosting static files like PDFs, images, videos, html pages and more.
S3 allows users to store objects (files) in buckets (containers) and organize them with keys (file names or paths). It offers features such as versioning, lifecycle management, and various storage classes, catering to different data availability, durability, and cost requirements.
In terms of security, S3 provides robust features including bucket policies, Access Control Lists (ACLs), and encryption in transit and at rest. Additionally, it integrates well with other AWS services and offers event notifications to enable automation and workflow orchestration.
Although S3 offers a myriad of useful features to design robust applications, what can make S3 an attractive solution for hosting static websites is a feature called S3 website endpoints.
S3 Website Endpoints

Amazon S3 website endpoints are a feature provided by Amazon S3 to enable static website hosting directly from an S3 bucket. With this feature, we can host a static website containing web pages in the form of HTML, CSS, JavaScript, and image files, without needing a traditional web server or additional services.
To use an S3 bucket for hosting a static website, we need to configure it appropriately by enabling the static website hosting feature. After enabling this feature, it’s essential to specify an index document, typically index.html. This document will serve as the default content returned to users when they access the root of the website endpoint.
This is what a website endpoint looks like 👇
html http://static-website.s3-website.us-east-1.amazonaws.com
Single Page Applications (SPA) and S3 Website Endpoints
Amazon S3 is great for hosting websites, especially when the content is static. That's why it's a popular choice for Single Page Applications (SPAs) which generally load just one main HTML file, named index.html, and dynamically update its content based on user interactions.
Now, speaking of our setup, we're designing our infrastructure for a NextJS site. NextJS is a powerful framework that offers various ways to render web pages. We've opted for a method called Static Site Generation (SSG), where pages are pre-built and saved as static files. This means when someone visits our website, they get these pre-built pages directly from S3, ensuring a speedy experience.
Even though our pages are statically generated, they can still behave dynamically after they're loaded. This means our website is kind of a blend, combining the speed of static sites with the interactivity of SPAs. We can think of it as a "hybrid" site, offering the best of both worlds.
📍 Checkpoint 1
So far we've learned that S3 website endpoints might serve as a potential solution to host a static website. The process to implement S3 website endpoints might look as follows:
- Create a new S3 bucket (Maybe using click-ops)
- Enable Static Website Hosting (Provide index document)
- Disable S3 "Block Public Access" setting (Access to S3 is blocked by default)
- Build our Static Site/SPA (Transpile React code into HTML, CSS and JavaScript files)
- Upload files to S3 bucket (e.g. Using bash script and aws CLI)
Challenges with S3 Website Endpoints
 While website endpoints may initially appear to be an ideal solution to host a single page application, they also present certain disadvantages. These disadvantages prompt us to reconsider the usage of website endpoints and potentially reevaluate our architecture thus far.
While website endpoints may initially appear to be an ideal solution to host a single page application, they also present certain disadvantages. These disadvantages prompt us to reconsider the usage of website endpoints and potentially reevaluate our architecture thus far.
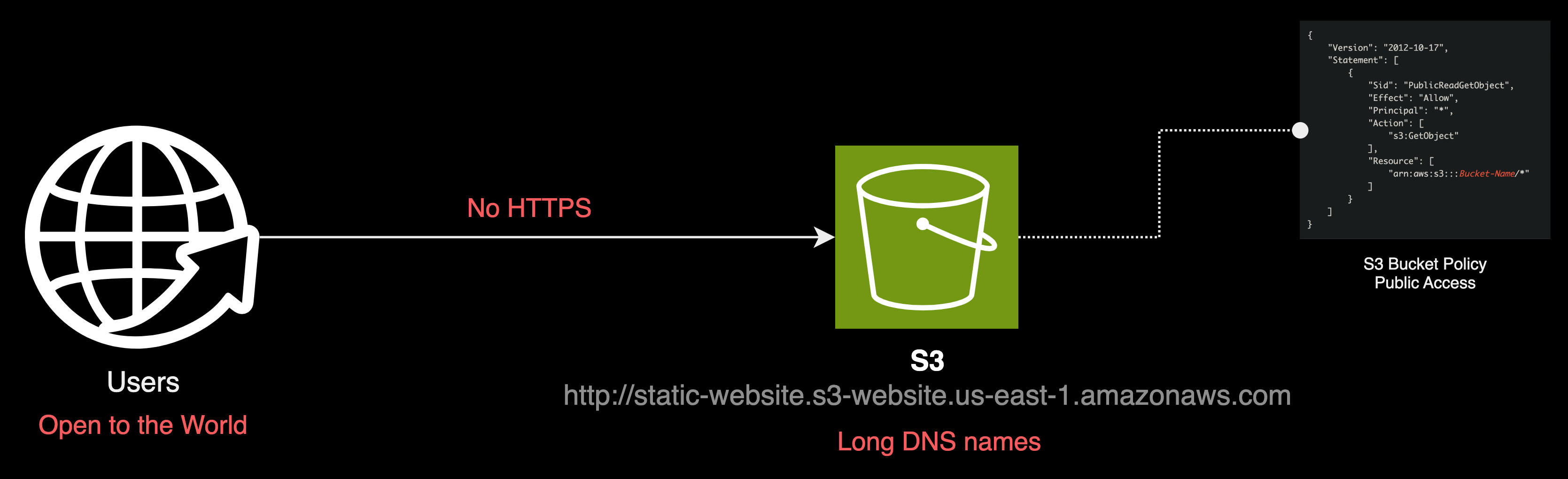
When considering an architecture centered around a singular S3 bucket with website endpoints enabled, we encounter three primary challenges:
- Unrestricted S3 Bucket Access
- No Support for HTTPS
- Lack of User-Friendly URLs
Unrestricted Bucket Access
While it's important to have a robust solution for hosting a static site, ensuring security is equally crucial. Improper management of public access to our S3 bucket can introduce security vulnerabilities.
If left unchecked, unauthorized individuals or malicious actors can access confidential information such as personal details, passwords, and API keys, leading to data leakage and breaches of privacy. The risk of “leaky buckets” is far from hypothetical; even renowned tech giants like McGraw-Hill have experienced such incidents. For more information on the implications of publicly exposed S3 buckets, check out this article by Laminar Security here.
No Support for HTTPS
Another challenge imposed by s3 website endpoints is their lack of HTTPS support. Without HTTPS data transferred between the client and the S3 bucket would be unencrypted. This makes it susceptible to eavesdropping attacks where an unauthorized third party can intercept and view the data.
Lack of User-Friendly URLs
Finally, the default URLs provided by S3 website endpoints are not user-friendly as they tend to be long and include the AWS region and the amazonaws.com domain, making them hard to remember and share.
For example, a typical S3 website endpoint generated by CloudFormation might look something like this: http://staticwebsitestack-objectst-websitebucket75c24d94-1a94k0cdpxntb.s3-website-us-east-1.amazonaws.com/. This can certainly impact the user experience, as users generally prefer shorter, more readable and easily memorable URLs. In addition, if CloudFormation is allowed to generate URL names randomly, it could change, potentially causing users to lose access to the site.
Overcoming S3 Website Endpoints Challenges
Having highlighted the challenges presented by S3 website endpoints, it's time to explore how integrating additional AWS services can help us address these issues. Notably, we'll discover that Amazon CloudFront plays a significant role in resolving most of these challenges.
Amazon CloudFront
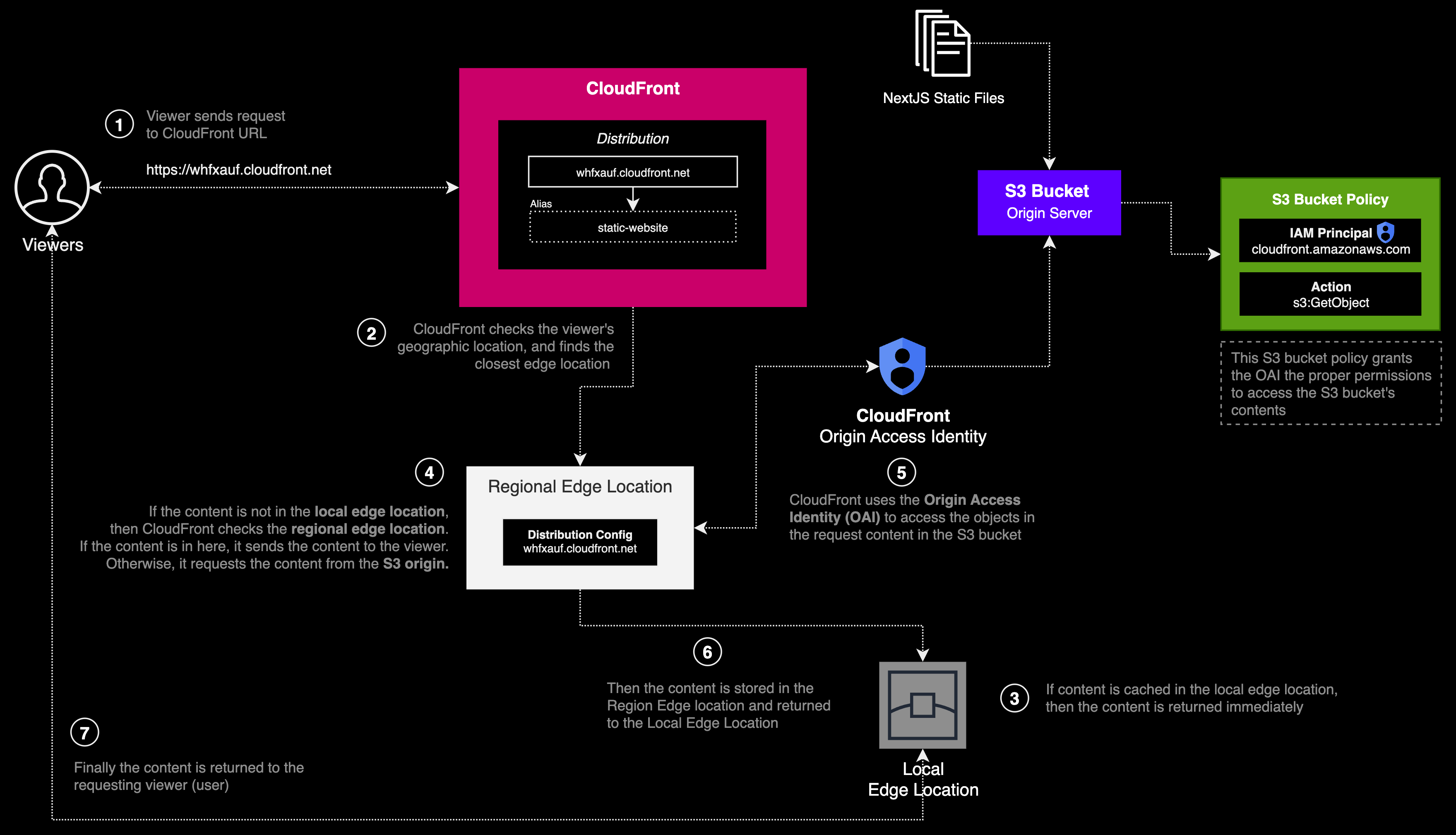
Amazon CloudFront is a Content Delivery Network (CDN). At its core, a CDN is a network of servers strategically positioned worldwide to distribute digital content such as web pages, videos, images, scripts, and style sheets to users both quickly and securely.
In CloudFront, these servers are referred to as edge locations. When a viewer (end user), requests content, CloudFront directs them to the nearest edge location, optimizing for the shortest possible latency (time delay) and ensuring high performance. If the requested content is cached in that edge location, CloudFront serves it immediately (also known as a cache hit). If not, the system fetches the content from a designated origin (also known as a cache miss) like an S3 bucket or an EC2 instance which you specify as the primary source of the content.
Another important concept in CloudFront is caching behavior. In CloudFront, a cache behavior is essential for determining how CloudFront responds to content requests and interacts with origin servers. One key aspect is the Path Pattern, which determines which requests the cache behavior affects based on the URL path. Then there’s the Origin, specifying the origin server from which CloudFront retrieves content when it’s not in the cache. Additionally, Cache and Origin Request Settings define how CloudFront should forward requests to the origin and how to cache the responses, influencing the forwarding of query strings, cookies, and HTTP headers.
Another critical element is the Viewer Protocol Policy, dictating whether CloudFront allows, redirects, or rejects HTTP and HTTPS requests. The cache behavior also outlines the Allowed HTTP Methods, specifying which HTTP methods, such as GET, POST, PUT, OPTIONS, DELETE, etc., are permissible. Time to Live (TTL) is also an important component, setting the duration that CloudFront caches content in its edge locations.
Moreover, cache behaviors incorporate Restrictions and Permissions, which encompass settings for signed URLs/Cookies, Geo-restrictions, and other content access permissions. Lastly, cache behaviors can designate which CloudFront function, or Lambda@Edge function to execute at different CloudFront events. Through these various aspects, we can optimize and control how content is delivered, potentially enhancing loading times, reducing latency, and improving security.
I get it, that’s quite a bit of information to digest in one seating. The intricacies of CloudFront is what make it in my humble opinion, one of the most fascinating services AWS offers.
However, the key focus for us at this point is understanding how we can use CloudFront to serve the files that comprise our SPA. As previously mentioned, an origin defines the source from which CloudFront will fetch content if it isn’t already cached in a Regional or Local Edge location.
Let’s explore how we can configure an S3 bucket to be accessible exclusively via a CloudFront distribution.
⛔ Restricting S3 Public Access
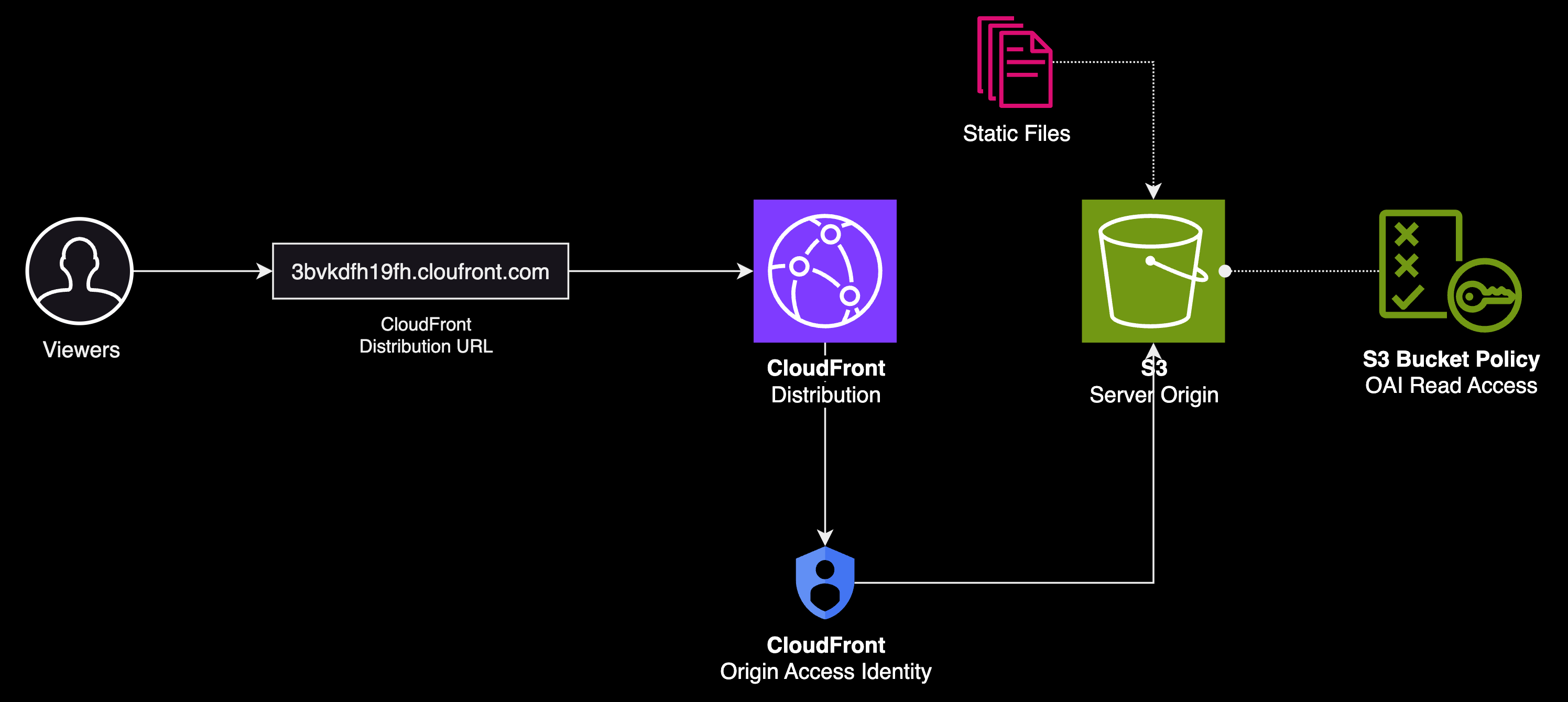
We can limit who has access to the static assets that make our SPA by allowing requests originating only from CloudFront. There are two methods we can leverage to enable authenticated requests to our S3 bucket origin, origin access identities (OAI) and origin access control (OAC).
An Origin Access Identity (OAI) is a special identity specific to CloudFront, which we can associate to S3 origins to secure either all or selected S3 content. The purpose of an OAI is to retrieve files from the bucket on behalf of users (in CloudFront lingo, viewers) who are requesting those files via CloudFront. This setup ensures that viewers cannot access the content directly using Amazon S3 website endpoint URLs, thereby, enhancing the security of our content.
Origin Access Control (OAC) is a newer mechanism to secure S3 bucket access. It supports certain functionalities for specific scenarios where OAI falls short or it requires extra workarounds. OAC provides support in all other AWS regions launched after December 2022, S3 server-side encryption with KMS, and dynamic requests (PUT and DELETE) to amazon S3.
We're opting for OAI for a couple of straightforward reasons. Firstly, our needs don't demand the newer features from OAC. Secondly, in the second half of this article, we're diving into AWS CDK, which currently doesn't support L2 constructs for origin access control. Not a huge deal! In fact, migrating from OAI to OAC is quite easy, we'd simply need to update the S3 bucket policy of the S3 origin to grant both OAI and OAC access to its contents.
So, no worries. We'll pivot to OAI for now and can switch to OAC once AWS catches up in the future.
📍 Checkpoint 2
Up until this point we've learned about the challenges of using S3 website endpoints, and how CloudFront can solve most of those issues. If we were to introduce CloudFront into the equation, our implementation processs might look something like this:
- Update S3 bucket
- Enable "Block All Public Access"
- Disable "Static Website Hosting"
- Upload our SPAs assets into the S3 bucket
- Use the AWS S3 CLI to upload our SPAs files
- ⚠️ NOTE: We'll learn how we can upload our SPA to our S3 bucket automatically in the second part of this article
- Create a CloudFront distribution
- Configure the distribution
- Add our S3 bucket as the server origin
✅ Ensuring HTTPS support
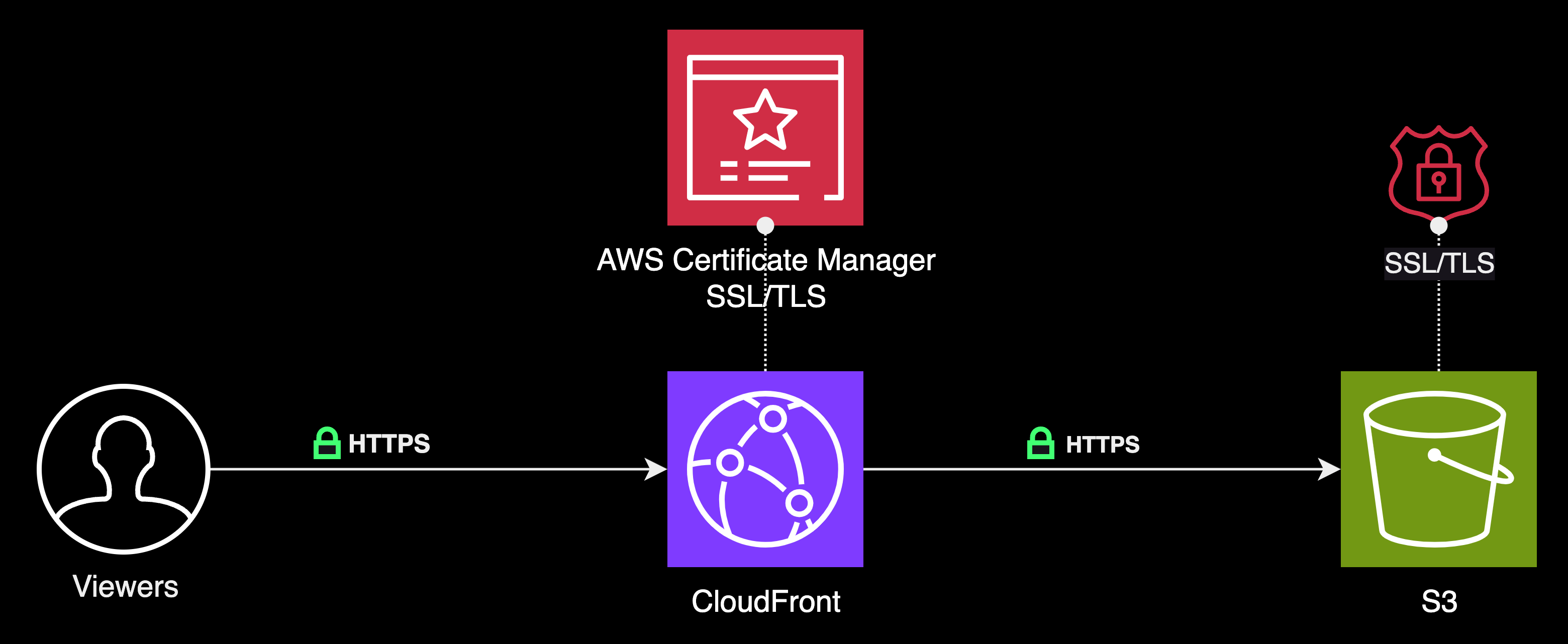
Now that we've learned we can restrict access to the S3 origin bucket by only allowing access to it via CloudFront using an origin access identity. Let's delve deeper into CloudFront and learn how we can secure our channels of communication.
CloudFront can be configured to enforce the use of HTTPS for enhanced security. To enable end-to-end encrypted communication, we must secure two communication connections.
The first connection that needs to be secured is the one between the viewers and CloudFront. Requiring HTTPS here ensures that the data exchanged between viewers and CloudFront is encrypted and secure during transit.
The second connection to secure is between CloudFront and the S3 origin server, where the static assets are stored. Securing this connection ensures that the content fetched by CloudFront from the S3 bucket is also transmitted securely.
Requiring HTTPS for communication between viewers and CloudFront
To facilitate HTTPS communication securely between viewers and CloudFront, we can modify settings in one or more cache behaviors within the CloudFront distribution. There are two primary methods to achieve this:
If we use the default CloudFront distribution domain name (for example, d111111abcdef8.cloudfront.net), we will need to alter the Viewer Protocol Policy setting for one or more cache behaviors to enforce HTTPS communication. When we configure it in this manner, CloudFront will automatically provide the necessary SSL/TLS certificate.
If we choose to our own domain name (e.g. via Route 53), such as sergiopichardo.com, we will be required to modify several CloudFront and Route 53 settings. Additionally, we must either obtain an SSL/TLS certificate from AWS Certificate Manager (ACM) or import a certificate from a third-party certificate authority into ACM or the IAM certificate store. For our purposes, we will be utilizing AWS ACM.
AWS Certificate Manager
ACM stands for AWS Certificate Manager, a service offered by Amazon Web Services (AWS). ACM handles the complexity around provisioning, deploying, and managing Secure Sockets Layer/Transport Layer Security (SSL/TLS) certificates, which are used to secure network communication and establish the identity of websites over the internet. Think of it like a digital ID card to verify a website.
Here’s how it works, step by step:
First off, we ask ACM for a certificate for our website’s domain, kind of like asking for an ID card. ACM makes sure we really own that domain, usually by checking an email or domain settings (this is called domain validation). Once ACM is sure we own the domain, ACM gives us the “okay” and provides us the certificate.
Next, we use associate this certificate with our CloudFront distribution. This is like putting your ID card to work! And the coolest part is that ACM will automatically renew this digital ID for us, so we don’t have to worry about it expiring.
Furthermore, ACM gives us a handy dashboard where we can see and manage all our certificates. It keeps them safe, controls who can access them, and keeps track of how they’re used. So, once everything’s set up, the certificate from ACM makes sure the communication between viewers and the CloudFront is secure.
Next, let's learn how we can secure the communication channel between CloudFront and the S3 origin bucket.
Requiring HTTPS for communication between CloudFront and an S3 origin
When the server origin of the content is an Amazon S3 bucket that supports HTTPS communication, CloudFront will forward requests to S3 using the same protocol that we, the viewers, employed to submit the requests. It’s crucial for us to keep in mind that S3 website endpoints do not support HTTPS.
To enforce HTTPS for communication between CloudFront and Amazon S3, we need to adjust the Viewer Protocol Policy value to either 'Redirect HTTP to HTTPS' or 'HTTPS Only'.
Additionally, when we employ HTTPS with an Amazon S3 bucket origin capable of supporting such communication, it is Amazon S3 that supplies the necessary SSL/TLS certificate. Now that's pretty cool!
📍 Checkpoint 3
Some of the necessary configurations, including the decision on whether to use HTTPS between the distribution and its viewers, are typically established during the creation of the distribution. As such, outlining these as a linear series of steps might be challenging. Nevertheless, a generalized outline of the steps can be represented as follows:
- Request an SSL/TLS certificate from Amazon ACM
- Create an Amazon CloudFront distribution
- Add the SSL/TLS certificate to the Amazon Certificate Manager
- Associate the SSL/TLS certificate with our CloudFront distribution
🤗 Providing User-Friendly URLs
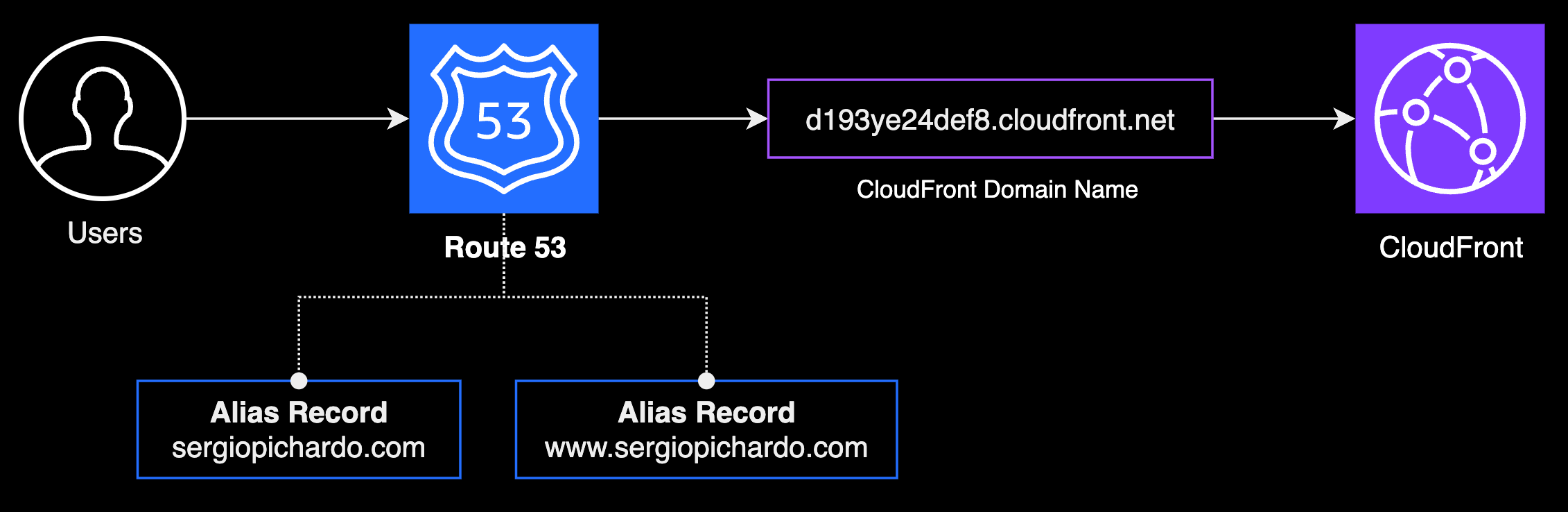
Next, we'll use Route 53 to create more user-friendly URLs. But first, let's gain a better understanding of DNS and Route 53.
The Domain Name Service (DNS)
The Domain Name Service (DNS) is a decentralized system that translates easy-to-remember domain names, such as www.example.com, into IP addresses, like 192.0.2.1, that computers use to recognize each other on the network. Think of it as the internet's phonebook: when you wish to access a website, your device looks up the site's IP address in the DNS before establishing a connection.
Route 53
We use Amazon Route 53, a scalable and highly available DNS service from AWS, to provide developers and businesses a reliable and cost-effective way to direct end-users to internet applications. Beyond primary DNS services, Route 53 offers additional features like domain registration, health checking services, and traffic management through routing policies (e.g. weighted, geo, etc...).
👉 The name for Route 53 comes from the fact that DNS servers respond to queries on port 53
Route 53 Integration with CloudFront
When we establish a distribution in CloudFront, we are assigned a domain name, such as d12345abcdwqr.cloudfront.net. To utilize a custom domain name like www.example.com, we can leverage Route 53 to create an alias record, linking our custom domain to the CloudFront distribution domain.
Routing traffic from a subdomain to an apex domain name
Finally, we will utilize Route 53 to set up user-friendly URLs by mapping a domain name, like example.com, directly to the CloudFront distribution domain name. Furthermore, we'll create an alias record to ensure that requests to a subdomain, such as www.example.com, are seamlessly redirected to the apex domain, for example, example.com.
📍 Checkpoint 4
Once we have gone through the process of configuring our S3 origin and HTTPS, the next step is to update DNS records to point to our CloudFront distribution:
- Map our domain name to the CloudFront distribution's default domain name
- Create a CNAME and add the alternative domain name
- Register a domain name (preferably with Route 53)
- (Optional): Transfer a domain name from a different account
URLs re-writes at the Edge
The Problem
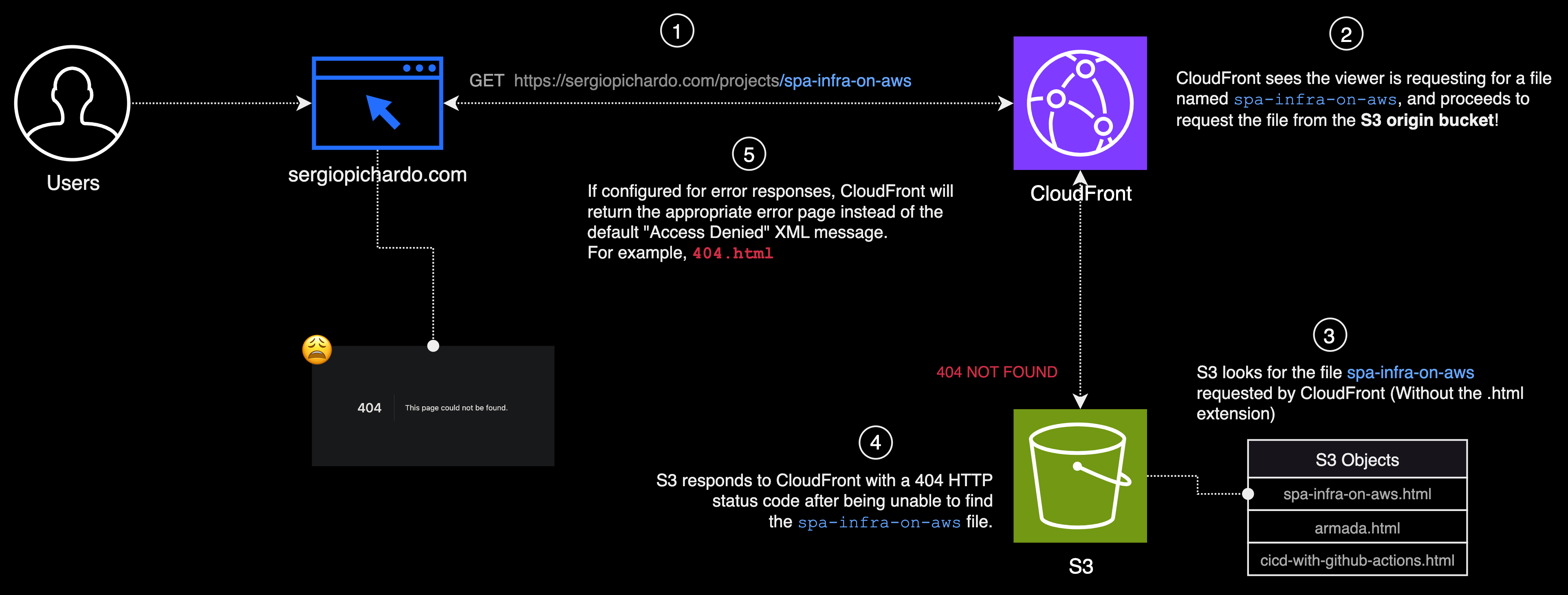
When we visit a webpage, like https://sergiopichardo.com/projects/spa-infra-on-aws, we’re sending a request that eventually reaches CloudFront. CloudFront then requests the page spa-infra-on-aws from the S3 origin. If S3 has the html page, it sends it back through CloudFront, and the viewer gets to see the page. But if S3 doesn’t have the page, it sends back a 404 HTTP status code, which basically means "Page Not Found". If we've set up CloudFront to support error responses, instead of just showing us the default "Access Denied" XML error message, it will show us a nicer, custom error page such as the 404.html that NextJS provides.
The Solution
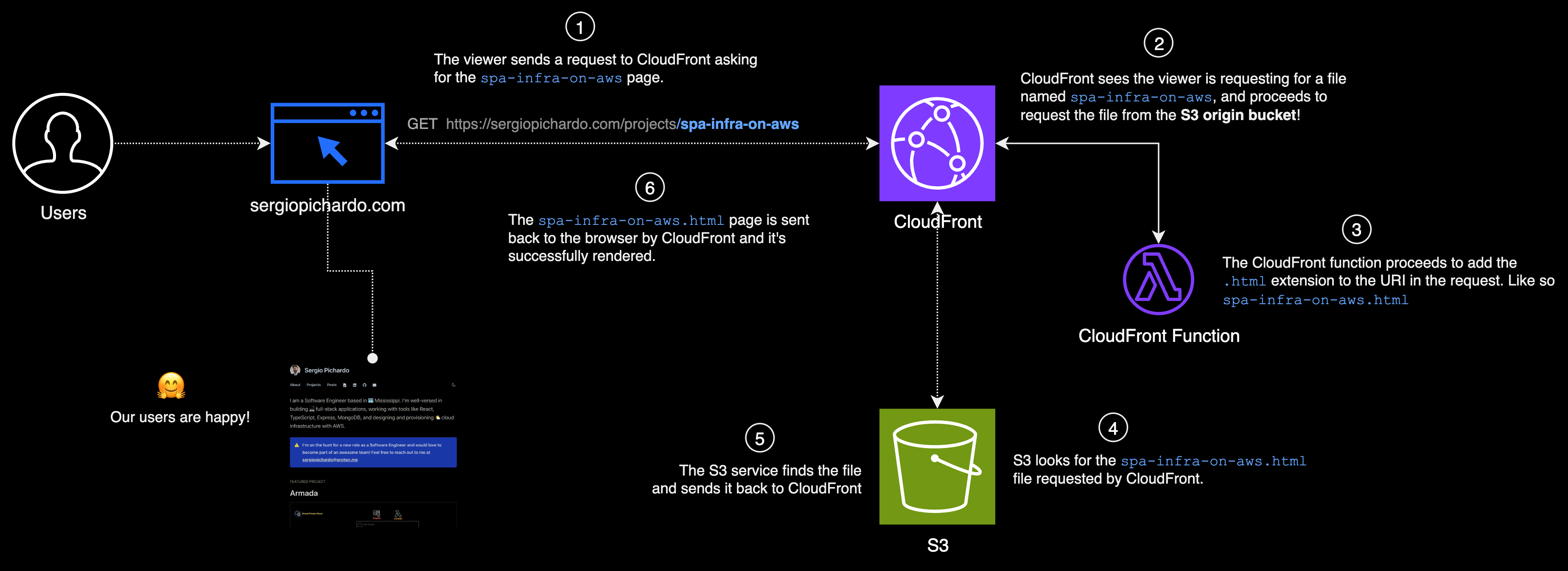
Just to be clear, the reason why the s3 origin is unable to find the file is because the request sent to S3 is for a file called spa-infra-on-aws and that files doesn't exist in the S3 bucket. However, what does exist in S3 is an html file named spa-infra-on-aws.html.
So, what we gotta do is find a way to request for the correct file by appending the .html extension, but only when the file being requested is not the index.html root document file.
We can achieve this by writing a piece of logic that re-writes the uri in the request. We have a couple options to consider, CloudFront functions and Lambda@Edge.
CloudFront functions vs Lambda@Edge
CloudFront Functions and Lambda@Edge both serve as extensions of the CloudFront CDN service, enabling customization of content delivery at the edge. While they seem to serve similar purposes, their use-cases, capabilities, and restrictions differ considerably:
CloudFront functions
- Run at CloudFront Edge locations, which are closer to users, ensuring minimal latency.
- Are designed for lightweight tasks, mainly focused on URL re-writes, headers manipulation, and simple request/response modifications.
- Have several limitations like being unable to access the request body, limited package size, lack of dynamic code evaluation, and no internet or filesystem access.
- Boast rapid execution times, usually less than 1ms, making them well-suited for high-frequency, low-latency tasks.
Lambda@Edge functions
- Run at CloudFront Regional Edge Caches, which are located in larger AWS regions.
- Can handle more complex tasks and provide functionalities such as reading request bodies, larger code packages, and prolonged execution times.
- Unlike regular Lambda functions, they have certain restrictions, like no VPC access, absence of environment variables, and no support for different Lambda layers or specific architectures.
- Offer more flexibility by supporting multiple languages and enabling access to additional AWS services.
Our main goal is to change URLs of files before they get to the S3 origin. In this scenario, CloudFront Functions are our best option. Why? Because they operate at Edge locations, which are close to our users, so things work faster.
These functions are designed just for tasks like changing URLs. On the other hand, Lambda@Edge can do a lot more. But using it just to change URLs seems excessive, especially since it's more complex and costs six times more than CloudFront Functions. So, since we just need to modify URLs, CloudFront Functions are the best choice. That's why we're choosing them.
📍 Checkpoint 5
We're done! The final step is to address our URL issues.
- Use a CloudFront function to adjust the URL of the file being requested, before it reaches the S3 origin.
Conclusion
We've covered the basics of hosting a single-page application on AWS. We discussed the pros and cons of using specific services. From storage with S3 to optimized delivery with CloudFront and secure access with the AWS Certificate Manager, we've crafted a robust architecture. While we touched on many points, there's always more to explore and refine. One enhancement could be adding a Web Application Firewall (WAF). Incorporating WAF can help protect our application from common web threats and ensure a safer user experience.
If you're interested in seeing how to actually set this up, take a look at my other tutorial where we dive into a hands-on approach 👇.
👉 👉 👉 Here's the second part of the article → 👈 👈 👈
Resources
-
Hosting a static Website using Amazon S3
-
Restricting access to an Amazon S3 origin (CloudFront)
-
Origin Access Control (CloudFront)
-
Migrating from OAI to OAC
-
Requiring HTTPS between viewers and CloudFront
-
Requiring HTTPS between CloudFront and an S3 origin
-
AWS CloudFront Architecture
-
Routing Traffic to a CloudFront distribution by using your domain name
-
Associate lambda with cloudfront
-
How to Associate SSL Cert with Amazon CloudFront
-
How to use a custom domain name with CloudFront and Route 53
-
Route 53 and CloudFront - step by step
-
How can I redirect one domain to another in Route 53?
-
Forward traffic from WWW subdomain to apex domain in AWS route 53
-
CloudFront Functions vs Lambda@Edge
-
URL Rewrite for Single Page Applications
-
CloudFront Functions – Run Your Code at the Edge with Low Latency at Any Scale